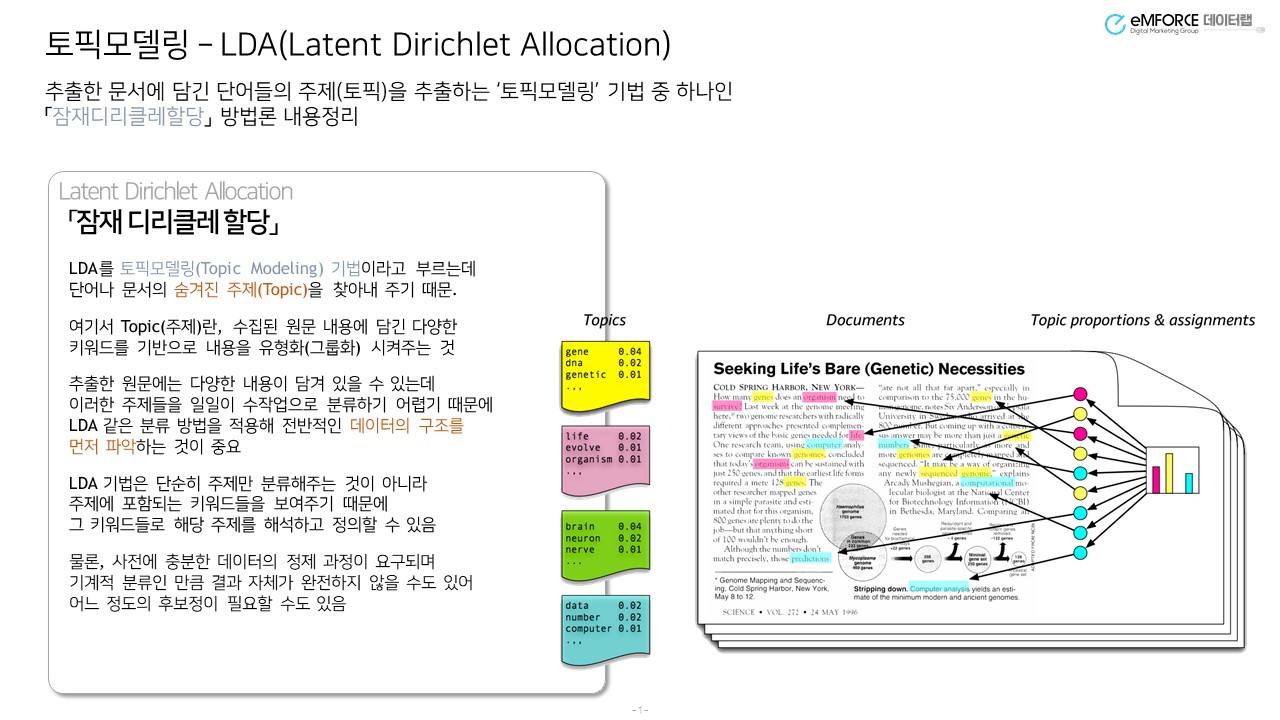
빅데이터에서 ‘빅(Big)’을 떼어내면 우리가 많이 들어본 ‘데이터’가 된다.
빅데이터라고 하니까 엄청 새로운 것처럼 생각되지만 실상은 ‘많은 양’의 데이터일 뿐이다.
잠깐, 여기서 많은 양의 데이터일 뿐이라고 하니까 오해를 살 여지가 있어서 덧붙이자면,
많은 양의 데이터라는 것이 구현되려면 실로 다양한 기술의 진보가 있어야 가능한 일이고
많은 양의 데이터라는 의미가 ‘한 종류’의 많은 양을 의미하는 것뿐만 아니라
다양한 종류의 데이터 간 ‘융합을 통한 많은 양’ 일 수 있으므로 새로울 수 있지만,
빅데이터라고 해서 (기존 데이터와는 다른) 전혀 새로운 접근일 필요가 없다는 것이다.
아니 그렇게 해서는 정말 안된다는 이야기를 하고 싶다.
데이터에서 의미 있는 결과를 도출하려면,
01. 그 데이터가 갖는 고유한 특성을 잘 이해해야 한다.
02. 그 데이터로 무엇을 할 수 있는지 알아야 한다.
03. 그 데이터로 무엇을 할 것인지 정해야 한다.
04. 그 데이터를 통해 어떤 결과가 나올 수 있는지 가늠해야 한다.
05. 그 데이터를 어떤 방법으로 분석할 수 있는지 알아야 한다.
당연한 얘기라서 시시하다고 생각될지 모르지만,
실제로 저런 부분을 간과하거나 중요하지 않다고 생각하는 사람들이 많은 것 같다.
당연한 얘기를 좀 더 해 보면,
01. 데이터의 고유한 특성에 대한 이해.
예를 들면, 내가 어떤 정보를 찾고자 할 때, 검색하게 되는 검색어도 채널에 따라 다를 수 있다.
네이버에서 정보를 찾을 때와 유튜브에서 정보를 찾을 때를 비교해 보면
처음에는 동일한 단어, 문구를 사용하더라도 검색을 하면 할수록 얻고자 하는 정보 유형에 따라,
혹은 해당 채널에서 제공하는 정보의 종류에 따라 조금씩 다르게 검색할 수 있다.
우리는 정보를 제공하는 다양한 채널의 차이를 경험하게 되기 때문이다.
만약 다양한 채널에서 얻게 되는 정보의 내용이 모두 동일하다면, 한 채널로의 쏠림 현상이
나타나겠지만 우리는 그렇지 않음을 알기 때문에 다양한 정보를 얻기 위해 다양한 채널을
이용하고 있는 것이며, 따라서 이러한 미세한 차이를 알아야 분석에 활용할 수 있다.
02. 데이터의 활용 범위와 한계에 대한 이해
데이터의 고유 특성을 알게 되면 어떤 궁금증을 해소해 줄 수 있는지 알아야 한다.
반대로 얘기하면 어떤 것은 알 수 없는지, 한계를 명확히 인지해야 한다.
특정 데이터가 빅데이터로 둔갑되었다고 해서 만능키가 될 수는 없다.
어떤 데이터가 어떤 한계가 있는지를 알아야 어떤 데이터가 필요한지 판단할 수 있게 된다.
03. 무엇을 알아볼 것인지에 대한 결정.
아마 이것 만큼은 당연하다고 생각하는 사람들이 많을 것이다.
아마 한 마디로 ‘Data Driven Marketing’이라는 거창한 말로 대답할지도 모르겠다.
일단 데이터를 쌓아 놓으면 언젠가, 어디엔가는 쓰겠지라고 생각하는 사람이 정말 많다.
이건 일단 예쁘게 디자인 뽑아봐 언젠가, 어디엔가는 쓰겠지라고 얘기하는 것과 같은 말이다.
심지어 데이터는 무턱대고 쌓을 경우 필요할 때 입맛에 안 맞으면 재작업이 만만치 않다.
04. 전략적 방향성에 대한 검증.
데이터 분석을 요구하는 사람들이 ‘우리는 이렇게 생각하고 있는데 정말 그런지 알고 싶어요’라고
하는 경우, 나는 그게 그렇게 반갑다. 목표도 목적도 명확하기 때문이다.
이런 경우 분석 과정에서 기존 질문에 대한 대답 외에도 새로운 내용이 발견되는 경우도 더러 있다.
데이터를 설계하는 과정에서도 비교적 깔끔하게 진행된다.
왜 그럴까?
가설이 있어야 데이터를 가장 효과적으로 빨리 다양하게 볼 수 있기 때문이다.
데이터 분석을 요구하는 많은 사람들이 일부러 관점을 좁혀서 이야기하지 않는 경우도 있는 것 같다.
이런 걸 봐달라고 좁혀서 이야기하면 마치 다른 부분을 안 볼 까 봐.
우리 브랜드에 대한 전반적인 소비자 인식이 궁금해요, 라며 퉁 치는 것 같다.
이런 경우는 몇 차례 구체적인 질문을 통해 대답을 이끌어 내야 한다.
예전에 어느 TV 강연 프로그램에서 본 적이 있는데 사람이 인공지능보다 나은 점이
‘몰라’라는 대답이 빠르다는 것이다. 즉, 인간은 아는지 모르는지에 대한 대답이 즉각적인데 비해,
인공지능은 내가 가진 것들을 하나씩 판단해야 하기 때문에 이 판단이 다 끝나야 대답할 수 있기
때문이란다. 물론 실제 물리적인 속도에 대한 것보다 처리 과정을 비교한 것이겠지만.
나는 실제 데이터를 분석하는 과정이 이와 같아야 한다고 생각한다.
내가 가장 궁금한 것에 대한 대답을 찾다 보면 오히려 다른 새로운 것들이 더 잘 보인다.
즉, 데이터는 내가 보고 싶은 부분부터 보는 것이고 그 과정에서 다양한 궁금증들이
꼬리에 꼬리를 물고 생겨나야 깊게 볼 수 있는 것이다. 가설과 증명이 탐색으로 이어져야
인사이트에 점점 가까워질 수 있다.
05. 데이터의 다양한 분석 방법에 대한 이해와 경험
이 부분은 고려 사항이라기보다는 학습과 경험이 필요한 부분이기는 하다.
사실 학습보다는 경험이 더 필요하다고 생각된다. 기술적인 방법을 아는 것뿐만 아니라
그 방법을 통했을 때의 결과를 어느 정도 예상할 수 있는 경험이 필요하다는 것이다.
그래서 단기적으로 고려해야 하는 사항으로 이야기하기에는 어폐가 있긴 하지만,
그럼에도 강조하고 싶다.
빅데이터와 관련된 여러 논란 중에 분석된 결과나 데이터 종류를 두고,
이게 빅데이터냐 아니냐 따지는 경우도 많은 것 같은데,
개인적인 생각이지만, 빅데이터를 기존 데이터와 굳이 구분 지으려는 태도 자체가
오히려 이상하지 않나 싶다.
빅데이터는 특정 데이터 종류를 지칭하지 않는다.
기술의 진보에 따라 이미 다양하게 산재해 있었던 정보들을 빠르게 데이터화 시킴으로써
탄생한 데이터 정도로 이해하는 게 맞지 않나 싶다.
따라서 빅데이터를 분석하겠다고 하는 것은, 빅데이터의 기술적 환경에 대한 이해를 넘어
빅데이터로 구현될 수 있는 데이터의 특성을 이해하려고 노력하는 것이 바람직하다.
빅데이터로 무엇을 할 수 있는지에 대한 질문이 아니라
우리는 어떤 정보들을 데이터로 구현할 것인가? 그 정보들이 데이터가 되면 어떤 역할을 할 수 있는가?
에 대한 고민이 선행되어야 한다는 것이다.
그냥 그런 끄적임.