안녕하세요
엠포스 빅데이터팀입니다.
저희 빅데이터팀에서는 SNS를 통한 사용자들의 트렌드 변화,
산업별 변화 등등 다양한 트렌드 및 인사이트 보고서를 발행하고 있습니다.
해당 카테고리글(방법론)에서는 산업 변화 및 다양한 인사이트 보고서에서
사용되고 있는 분석 방법들을 간략히 소개드리는 창구가 될 것 같습니다.
이번에 소개드리는 방법은 토픽모델링 중 LDA 기법을 적용한 텍스트 분석 방법인데요.
Datalab site에 게시된 보고서 중 <<비대면 시대>>의 인사이트 도출 과정에 쓰인 방법 중 하나인 토픽모델링으로 기본적인 방향과, 접근 방향, 코딩 내용 등은 간략히 파일을 첨부해 두었으며, 본문에서는 토픽 모델링의 개념적인 내용들을 말씀드리고자 합니다.
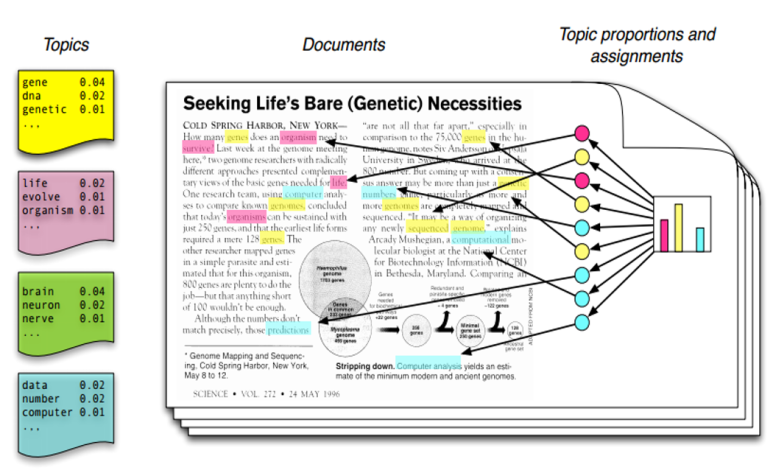
그림1은 토픽모델링을 설명하면 항상 나오는 사진인데 이렇게 기사 문서에 담긴 텍스트들의 키워드를 하나씩 뽑아 키워드를 토픽별로 인덱싱하여 분류합니다.
위 그림을 좀 더 살펴보면 좌측상단 노란색 그림 안에 gene, dna, genetic이라는 단어들이 상위 값으로 분포하고 있는데요. 해당 키워드들을 살펴볼 때,
해당 토픽은 “유전자”라는 내용의 주제로 추론을 해볼 수 있겠네요.
이처럼 토픽모델링은 각 단어나 문서들의 집합에 대해 숨겨진 주제를 찾아내어 문서나 키워드별로 주제끼리 묶어주는 비지도학습 알고리즘 중 하나입니다.
LDA를 사용하는 토픽모델링은 문서가 있고, 그 안에 단어가 있다면
확률분포 중 하나인 디리클레의 분포를 가정하고, 번호가 매겨진 토픽 안에 문서와 단어들을 하나씩 넣어보며 잠재적인 의미(토픽)들을 찾아주는 과정입니다.
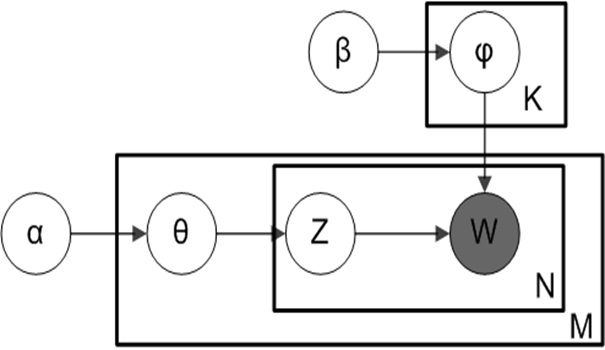
α, β, K : 디리클레 분포 하이퍼 파라미터 값
M: 문서 개수
N: 문서에 속한 단어의 갯수
θ: 문서의 토픽 디리클레 분포
φ: 주제의 단어
Z: 해당 단어가 속한 토픽의 번호
W : 실제 관측 가능한 값
그림2은 LDA 모델을 설명하기 위해 자주 사용하는 그림인데요.
W는 우리가 실제 관측할 수 있는 단어들을 뜻하고, 상자 모양들로 정해진 값들은 모델이 파라미터 값에 의해 계속 반복되어 학습하며 값이 변경됩니다.
첨부된 파일은 LDA를 적용한 토픽모델링 방법론을 만든 논문입니다.
α, β, K 파라미터들에 대해 좀 더 말을 하자면
α의 값은 문서들의 토픽 분포를 얼마나 밀집되게 할 것인지에 대한 설정 값
β의 값은 문서내 단어들의 토픽 분포를 얼마나 밀집되게 할 것인지에 대한 설정 값입니다.
K는 토픽을 몇개로 설정할 것인지에 대한 설정 값으로 되어 있습니다.
해당 파라미터들은 내가 원하는 주제끼리 문서, 단어들이 묶여있는지 계속 학습을 해나가며 파라미터 값을 변경합니다.
간단한 문서들을 통해 LDA 모델링 과정을 예시로 들면,
1번 문서 : 문고리거래 하실분
2번 문서 : 가방 나눔합니다. 문고리드림
3번 문서 : 비대면거래로 합니다. 택배로 할께요.
기본적으로 형태소 분석기의 추가 사전 정의 없이
명사를 추출한다면 추출된 결과는 다음과 같습니다.
1번 문서 : 문고리, 거래
2번 문서 : 가방, 나눔, 문고리, 드림
3번 문서 : 비대면, 거래, 택배
추출된 명사들을 통해 본격적으로 LDA 학습 과정을 말씀드리면
첫번째. 모든 문서와 문서 속 단어들을 임의의 토픽 번호 부여

두번째. 토픽-문서의 단어 분포를 계산

1번문서의 문고리 단어가 topic1로 배정되어 1의 값이 생기고, LDA 파라미터 값인 α를 0.01로 설정하면 그 값을 같이 더해줍니다.
그렇게 1번문서에는 topic3에 배정된게 없지만 최소한의 값을 배정해줍니다.
(이는 추후에 토픽에 단어, 문서가 존재할 확률을 구할 때 0이 나오는 것을 방지하기 위해 α 파라미터의 값을 0이 아닌 값을 지정 해줍니다.)
세번째. 토픽-단어 분포 계산

표2 토픽-문서단어 분포계산과 같이, 표3에서도 임의로 배정된 토픽-단어 분포를 계산해줍니다. “문고리” 단어의 경우 3번 토픽에 지정되어 있지않으나,
β값을 0.001로 지정함으로써 최소한의 값을 부여했습니다.
네번째. 단어 하나를 제외한 나머지 토픽-단어, 문서의 분포를 고정시킨다.

다섯번째. 미분류된 키워드의 토픽을 선정한다.
해당 과정에서부터는 1번 문서에 속한 ‘문고리’의 키워드를 topic1~topic3에 확률을 계산합니다.
1번 문서 내 topic1이 있을 확률 : 1.01/3.03 = 0.333
(이 때 분모의 경우 1번 토픽 내 문서 분포 합입니다. )
1번 토픽 내 단어가 ‘문고리’일 확률 : 1.001/3.007 = 0.332
(이 때 분모의 경우 1번 토픽 내 키워드 분포 합입니다.)
마지막으로 1번 문서의 ‘문고리’가 topic1일 확률 0.333*0.332=0.110이 됩니다.
위처럼 1번 문서 내 topic2이 있을 확률,
1번 문서 내 topic3이 있을 확률 모두 구해줍니다.
해당 과정을 모두 반복하면 가장 높은 확률을 가진 토픽에 해당 단어와 문서가 분류됨으로써 LDA학습은 완료가 됩니다.
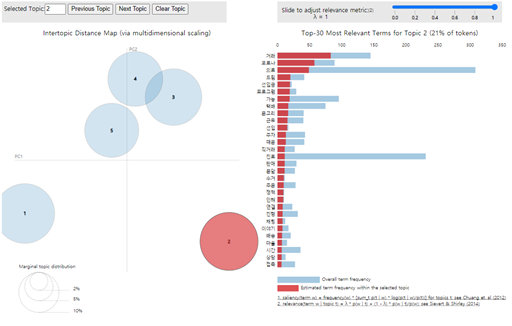
이렇게 각 문서, 단어별로 토픽들을 선정해주고 인덱스된 토픽에 대해
분석가의 도메인 지식과 키워드에 대한 이해로 주제들을 끄집어내는 과정이 추가로 필요한 부분입니다.
이로써 문서-단어 분류 기법 중 토픽모델링-LDA는 완료가 됩니다
LDA라는 기법이 돌아가는 과정은 한번 완료되었으나,
의미 있는 인사이트들을 얻으려면 당연히 더 많은 과정이 필요합니다.
추론된 주제들로 분류된 문서들과 단어들의 맥락을 다시 살핀 뒤, 모델을 계속 조정해보거나 혹은 단어들을 대치한다거나,
해석에 불용이한 문서들을 키워드로 찾아내어 제거한다거나,
사용자 사전을 조정하여 추출되는 단어들을 조정하는 등등 많은 전처리 과정을 반복하기도 하구요.
위 과정에 더하여 LDA로 학습된 모델을 평가하는 perplexity, Coherence Model 등의 지표가 있으니 이 지표들을 적용하여 더욱 섬세한 모델링을 만들어냅니다.
또한 데이터 분석의 끝은 이게 아니기에, 해당 방법론으로만 끝낼 수는 없습니다.
LDA는 방대한 양의 문서들이 어떤 내용을 말하고 있는지에 대한 큰 맥락들을 크게 묶어 살펴보게 해주는 기법이라고 할 수 있습니다.
그렇기 때문에 추가적으로 다른 방법들과 함께 사용하며 텍스트들을 살펴 보며 인사이트를 얻어내는 것이 중요하다고 생각합니다.
간략히 python을 통한 LDA 진행 과정 방법들이 기재된 파일도 첨부되어 있습니다.
해당 글을 통해 전체적인 흐름에 대해 살펴보는 과정이 필요하다고 하시면 보는 것이 도움이 되실 것이라 생각합니다.